

Progress bars are one of the most common, familiar UI components in our lives. We see them every time we download a file, install software, or attach something to an email. They live in our browsers, on our phones, and even on our TVs.
And yet—making a good progress bar is a surprisingly complex task!
In this post I'll describe all of the components of making a quality progress bar for the web, and hopefully by the end you'll have a good understanding of everything you'd need to build your own.
This post describes everything I had to learn (and some things I didn't!) to make celery-progress, a library that hopefully makes it easy to drop in dependency-free progress bars to your Django/Celery applications.
That said, most of the concepts in this post should translate across all languages/environments, so even if you don't use Python you probably can learn something new.
Why Progress Bars?
This might be obvious, but just to get it out of the way—why do we use progress bars?
The basic reason is to provide users feedback for something that takes longer than they are used to waiting. According to kissmetrics, 40% of people abandon a website that takes more than 3 seconds to load. And while you can use something like a spinner to help mitigate this wait, a tried and true way to communicate to your users while they're waiting for something to happen is to use a progress bar.
Generally progress bars are great whenever something takes longer than a few seconds and you can reasonably estimate its progress over time.

Some examples where progress bars can be useful include:
- When your application first loads (if it takes a long time to load)
- When processing a large data import
- When preparing a file for download
- When the user is in a queue waiting for their request to get processed
The Components of a Progress Bar
Alright, with that out of the way lets get into how to actually build these things!
It's just a little bar filling up across a screen. How complicated could it be?
Actually, quite!
The following components are typically a part of any progress bar implementation:
- A front-end, which typically includes a visual representation of progress and (optionally) a text-based status.
- A backend that will actually do the work that you want to monitor.
- One or more communication channels for the front end to hand off work to the backend.
- One or more communication channels for the backend to communicate progress to the front-end.
Immediately we can see one inherent source of complexity. We want to both do some work in the backend and show that work happening on the frontend. This immediately means we will be involving multiple processes that need to interact with each other asynchronously.
These communication channels are where much of the complexity lies. In a relatively standard Django project, the front-end browser might submit an AJAX HTTP request (JavaScript) to the backend web app (Django) which in turn might pass that request along to the task queue (Celery) via a message broker (RabbitMQ/Redis). Then the whole thing needs to happen in reverse to get information back to the front end!
The entire process might look something like this:
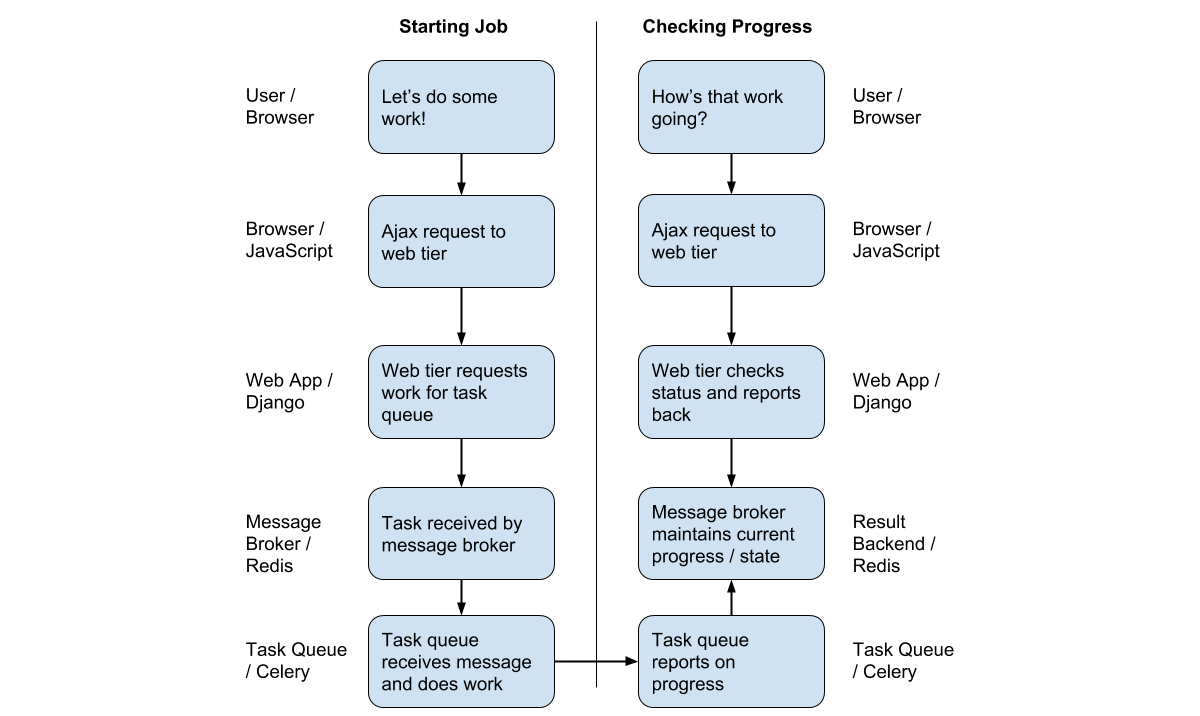
Let's dive into all of these components and see how they work in a practical example.
The Front End
The front end is definitely the easiest part of the progress bar. With just a few lines of HTML/CSS you can quickly make a decent looking horizontal bar using the background color and width attributes. Splash in a little JavaScript to update it and you're good to go!
See the Pen Simple Progress Bar UI by Cory Zue (@Cory-Zue) on CodePen.
The Backend
The backend is equally simple. This is essentially just some code that's going to execute on your server to do the work you want to track. This would typically be written in whatever application stack you're using (in this case Python and Django). Here's an overly simplified version of what the backend might look like:
def do_work(list_of_work):
for work_item in list_of_work:
do_work_item(work_item)
return 'work is complete'
Doing the Work
Okay so we've got our front-end progress bar, and we've got our work doer. What's next?
Well, we haven't actually said anything about how this work will get kicked off. So let's start there.
The Wrong Way: Doing it in the Web Application
In a typical ajax workflow this would work the following way:
- Front-end initiates request to web application
- Web application does work in the request
- Web application returns a response when done
In a Django view that would look something like this:
def my_view(request):
do_work()
return HttpResponse('work done!')
The problem here is that the do_work function might do a lot of work that takes a long time
(if it didn't, it wouldn't make sense to add a progress bar for it).
Doing a lot of work in a view is generally considered a bad practice for several reasons, including:
- You create a poor user experience, since people have to wait for long requests to finish
- You open your site up to potential stability issues with lots of long-running, work-doing requests (which could be triggered either maliciously or accidentally)
For these reasons, and others, we need a better approach for this.
The Better Way: Asynchronous Task Queues (aka Celery)
Most modern web frameworks have created asynchronous task queues to deal with this problem. In Python the most common one is Celery. In Rails there is Sidekiq (among others). The details between task systems vary, but the fundamental principles of them are the same. Basically, instead of doing work in an HTTP request that could take arbitrary long—and be triggered with arbitrary frequency—you stick that work in a queue and you have background processes—often referred to as workers—that pick the jobs up and execute them.
This asynchronous architecture has several benefits, including:
- Not doing long-running work in web processes
- Enabling rate-limiting of the work done—work can be limited by the number of worker-processes available
- Enabling work to happen on machines that are optimized for it, for example, machines with high numbers of CPUs
The Mechanics of How this Works
The basic mechanics of this are relatively simple, and involve three main components: the client(s), the worker(s), and the message broker.
The client is primarily responsible for the creation of new tasks. In our example, the client is the Django application, which creates tasks on user input via a web request.
The workers are the actual processes that do the work. These are our Celery workers. You can have an arbitrary number of workers running on arbitrary many machines, which allows for high availability and horizontal scaling of task processing.
The client and task queue talk to each other via a message broker, which is responsible for accepting tasks from the client(s) and delivering them to the worker(s). The most common message broker for Celery is RabbitMQ, although Redis is also a commonly used and feature complete message broker.

When building a standard celery application you will typically focus on the client and worker code. The message broker is a piece of infrastructure that you have to stand up and configure—but beyond that can (mostly) be ignored.
Example
While this all sounds rather complicated, Celery does a good job making it quite easy for us via nice programming abstractions.
To convert our work-doing function to something that can be executed asynchronously, all we have to do is add a special decorator:
from celery import task
# this decorator is all that's needed to tell celery this is a worker task
@task
def do_work(list_of_work):
for work_item in list_of_work:
do_work_item(work_item)
return 'work is complete'
Once we've marked the function as a task, calling it asynchronously from the Django client is similarly straightforward—we
just have to add a .delay() method call.
def my_view(request):
# the .delay() call here is all that's needed
# to convert the function to be called asynchronously
do_work.delay()
# we can't say 'work done' here anymore because all we did was kick it off
return HttpResponse('work kicked off!')
With just a few extra lines of code we've converted our work to an asynchronous architecture! As long as you've got your worker and broker processes configured and running this should just work.
Tracking the Progress
Alrighty, so we've finally got our task running in the background. But now we want to track progress on it. So how does that work?
We'll again need to do a few things. First we'll need a way of tracking progress within the worker job. Then we'll need to communicate that progress all the way back to our front-end so we can update the progress bar on the page. Once again, this ends up being quite a bit more complicated than you might think!
Using an Observer Object to Track Progress in the Worker
Readers of the seminal Gang of Four's Design Patterns might be familiar with the observer pattern. The typical observer pattern includes a subject which tracks state, as well as one or more observers that do something in response to state. In our progress scenario, the subject is the worker process/function that is doing the work, and the observer is the thing that is going to track the progress.
There are many ways to link the subject and the observer, but the simplest is to just pass the observer in as an argument to the function doing the work.
That looks something like this:
@task
def do_work(list_of_work, progress_observer):
total_work_to_do = len(list_of_work)
for i, work_item in enumerate(list_of_work):
do_work_item(work_item)
# tell the progress observer how many out of the total items we have processed
progress_observer.set_progress(i, total_work_to_do)
return 'work is complete'
Now all we have to do is pass in a valid progress_observer and voila, our progress will be tracked!
Getting Progress Back to the Client
You might be thinking "wait a minute… you just called a function called set_progress, you didn't actually do anything!"
True! So how does this actually work?
Remember—our goal is to get this progress information all the way up to the webpage so we can show our users what's going on. But the progress tracking is happening all the way in the worker process! We are now facing a similar problem we had with handing off the asynchronous task earlier.
Thankfully Celery also provides a mechanism for passing messages back to the client. This is done via a mechanism called result backends, and, like brokers, you have the option of several different backends. Both RabbitMQ and Redis can be used as brokers and result backends and are reasonable choices. And—while there is technically no coupling between the broker and the result backend—it almost always makes sense to use the same tool for both.
Anyway, like brokers, the details typically don't come up unless you're doing something pretty advanced, but the point is that you stick the result from the task somewhere (with the task's unique ID), and then other processes can get information about tasks by ID by asking the backend for it.
In Celery this is abstracted quite well via the state associated with the task.
The state allows us to set an overall status, as well as attach arbitrary metadata to the task.
This is a perfect place to store our current and total progress.
First we have to get a task. We can do this by using the bind=True option in the decorator,
which will then pass the celery Task object as the first argument (typically labeled self, by convention):
@task(bind=True)
def do_work(self, list_of_work, progress_observer):
task = self
# rest of function is the same
Then whenever we want, we can call update_state on this task object:
task.update_state(
state=PROGRESS_STATE,
meta={
'current': current,
'total': total,
}
)
from celery.result import AsyncResult
result = AsyncResult(task_id)
print(result.state) # will be set to PROGRESS_STATE
print(result.info) # metadata will be here
Getting Progress Updates to the Front End
Now that we can get progress updates out of the workers / tasks and into any other client, the final step is to just get that information to the front end and display it to the user.
If you want to get fancy you can use something like websockets to do this in real time, but the simplest version is to just poll a URL every so often to check on progress. We can serve the progress information up as JSON via a Django view and handle the rendering client-side.
Django view:
def get_progress(request, task_id):
result = AsyncResult(task_id)
response_data = {
'state': result.state,
'details': result.info,
}
return HttpResponse(json.dumps(response_data), content_type='application/json')
Django URL config:
urlpatterns = [
# other url configs here here...
url(r'^(?P<task_id>[\w-]+)/$', views.get_progress, name='task_status')
]
JavaScript code:
function updateProgress (progressUrl) {
fetch(progressUrl).then(function(response) {
response.json().then(function(data) {
// update the appropriate UI components
setProgress(data.state, data.details);
setTimeout(updateProgress, 500, progressUrl);
});
});
}
var progressUrl = '{% url "task_status" task_id %}'; // django template usage
updateProgress(progressUrl);
Putting it All Together
This has been quite a lot of detail on what is—on its face—a very simple and everyday part of our lives with computers! I hope you've learned something.
If you need a simple way to make progress bars for you django/celery applications you can check out celery-progress—a library I wrote to help make all of this a bit easier. There is also a demo of it in action. And a complete working example can also be found in SaaS Pegasus—a Django starter kit for your next big project.
Questions? Comments? Drop me a line and I'll be happy to respond.
If you'd like to get notified whenever I publish content like this on building things with Python and Django, please sign up to receive updates below.